СИђ№╝џС╗ђС╣ѕТў»ТюђС╝ўС║їтЈЅТаЉ№╝Ъ
С╗јТѕЉСИфС║║уљєУДБТЮЦУ»┤№╝їТюђС╝ўС║їтЈЅТаЉт░▒Тў»С╗јти▓у╗ЎтЄ║уџёуЏ«ТаЄтИдТЮЃу╗Њуѓ╣(тЇЋуІгуџёу╗Њуѓ╣) у╗ЈУ┐ЄСИђуДЇТќ╣т╝Јуџёу╗ётљѕтйбТѕљСИђТБхТаЉ.Сй┐ТаЉуџёТЮЃтђ╝Тюђт░Ј. ТюђС╝ўС║їтЈЅТаЉТў»тИдТЮЃУи»тЙёжЋ┐т║дТюђуЪГуџёС║їтЈЅТаЉсђѓТа╣ТЇ«у╗Њуѓ╣уџёСИфТЋ░№╝їТЮЃтђ╝уџёСИЇтљї№╝їТюђС╝ўС║їтЈЅТаЉуџётйбуіХС╣ЪтљёСИЇуЏИтљїсђѓт«ЃС╗гуџётЁ▒тљїуѓ╣Тў»№╝џтИдТЮЃтђ╝уџёу╗Њуѓ╣жЃйТў»тЈХтГљу╗Њуѓ╣сђѓТЮЃтђ╝УХіт░Јуџёу╗Њуѓ╣№╝їтЁХтѕ░Та╣у╗Њуѓ╣уџёУи»тЙёУХіжЋ┐
т«ўТќ╣т«џС╣Ѕ№╝џ
тюеТЮЃСИ║wl№╝їw2№╝їРђд№╝їwnуџёnСИфтЈХтГљТЅђТъёТѕљуџёТЅђТюЅС║їтЈЅТаЉСИГ№╝їтИдТЮЃУи»тЙёжЋ┐т║дТюђт░Ј(тЇ│С╗БС╗иТюђт░Ј)уџёС║їтЈЅТаЉуД░СИ║ТюђС╝ўС║їтЈЅТаЉТѕќтЊѕтцФТЏ╝ТаЉсђѓ
С║ї№╝џСИІжЮбтЁѕт╝ёТИЁтЄаСИфтЄаСИфТдѓт┐х№╝џ
1.Уи»тЙёжЋ┐т║д
тюеТаЉСИГС╗јСИђСИфу╗Њуѓ╣тѕ░тЈдСИђСИфу╗Њуѓ╣ТЅђу╗ЈтјєуџётѕєТћ»ТъёТѕљС║єУ┐ЎСИцСИфу╗Њуѓ╣жЌ┤уџёУи»тЙёСИіуџётѕєТћ»ТЋ░уД░СИ║т«ЃуџёУи»тЙёжЋ┐т║д
2№╝јТаЉуџёУи»тЙёжЋ┐т║д
сђђТаЉуџёУи»тЙёжЋ┐т║дТў»С╗јТаЉТа╣тѕ░ТаЉСИГТ»ЈСИђу╗Њуѓ╣уџёУи»тЙёжЋ┐т║дС╣Ітњїсђѓтюеу╗Њуѓ╣ТЋ░уЏ«уЏИтљїуџёС║їтЈЅТаЉСИГ№╝їт«їтЁеС║їтЈЅТаЉуџёУи»тЙёжЋ┐т║дТюђуЪГсђѓ
3№╝јТаЉуџётИдТЮЃУи»тЙёжЋ┐т║д(Weighted Path Length of Tree№╝їу«ђУ«░СИ║WPL)
сђђсђђу╗Њуѓ╣уџёТЮЃ№╝џтюеСИђС║Џт║ћућеСИГ№╝їУхІС║ѕТаЉСИГу╗Њуѓ╣уџёСИђСИфТюЅТЪљуДЇТёЈС╣Ѕуџёт«ъТЋ░сђѓ
сђђсђђу╗Њуѓ╣уџётИдТЮЃУи»тЙёжЋ┐т║д№╝џу╗Њуѓ╣тѕ░ТаЉТа╣С╣ІжЌ┤уџёУи»тЙёжЋ┐т║дСИјУ»Цу╗Њуѓ╣СИіТЮЃуџёС╣ўуД»сђѓ
сђђсђђТаЉуџётИдТЮЃУи»тЙёжЋ┐т║д(Weighted Path Length of Tree)№╝џт«џС╣ЅСИ║ТаЉСИГТЅђТюЅтЈХу╗Њуѓ╣уџётИдТЮЃУи»тЙёжЋ┐т║дС╣Ітњї№╝їжђџтИИУ«░СИ║№╝џ
тЁХСИГ№╝џ
nУАеуц║тЈХтГљу╗Њуѓ╣уџёТЋ░уЏ«
wiтњїliтѕєтѕФУАеуц║тЈХу╗Њуѓ╣kiуџёТЮЃтђ╝тњїТа╣тѕ░у╗Њуѓ╣kiС╣ІжЌ┤уџёУи»тЙёжЋ┐т║дсђѓ
ТаЉуџётИдТЮЃУи»тЙёжЋ┐т║дС║дуД░СИ║ТаЉуџёС╗БС╗исђѓ
СИЅ№╝џућеСИђСИфСЙІтГљТЮЦуљєУДБСИђСИІС╗ЦСИіТдѓт┐х
сђљСЙІсђЉу╗Ўт«џ4СИфтЈХтГљу╗Њуѓ╣a№╝їb№╝їcтњїd№╝їтѕєтѕФтИдТЮЃ7№╝ї5№╝ї2тњї4сђѓТъёжђатдѓСИІтЏЙТЅђуц║уџёСИЅТБхС║їтЈЅТаЉ(У┐ўТюЅУ«ИтцџТБх)№╝їт«ЃС╗гуџётИдТЮЃУи»тЙёжЋ┐т║дтѕєтѕФСИ║№╝џ
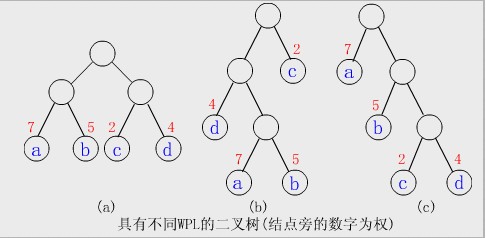
(a)WPL=7*2+5*2+2*2+4*2=36
(b)WPL=7*3+5*3+2*1+4*2=46
(c)WPL=7*1+5*2+2*3+4*3=35
тЁХСИГ(c)ТаЉуџёWPLТюђт░Ј№╝їтЈ»С╗ЦжфїУ»Ђ№╝їт«Ѓт░▒Тў»тЊѕтцФТЏ╝ТаЉсђѓ
Т│еТёЈ№╝џ
РЉа тЈХтГљСИіуџёТЮЃтђ╝тЮЄуЏИтљїТЌХ№╝їт«їтЁеС║їтЈЅТаЉСИђт«џТў»ТюђС╝ўС║їтЈЅТаЉ№╝їтљдтѕЎт«їтЁеС║їтЈЅТаЉСИЇСИђт«џТў»ТюђС╝ўС║їтЈЅТаЉсђѓ
РЉА ТюђС╝ўС║їтЈЅТаЉСИГ№╝їТЮЃУХітцДуџётЈХтГљуд╗Та╣УХіУ┐Љсђѓ
РЉб ТюђС╝ўС║їтЈЅТаЉуџётйбТђЂСИЇтћ»СИђ№╝їWPLТюђт░Ј
тЏЏ.тЊѕтцФТЏ╝у«ЌТ│Ћ
т»╣С║ју╗Ўт«џуџётЈХтГљТЋ░уЏ«тЈітЁХТЮЃтђ╝ТъёжђаТюђС╝ўС║їтЈЅТаЉуџёТќ╣Т│Ћ№╝їућ▒С║јУ┐ЎСИфу«ЌТ│ЋТў»тЊѕтцФТЏ╝ТЈљтЄ║ТЮЦуџё№╝їТЋЁуД░тЁХСИ║тЊѕтцФТЏ╝у«ЌТ│ЋсђѓтЁХтЪ║ТюгТђЮТЃ│Тў»№╝џ
сђђсђђ(1)Та╣ТЇ«у╗Ўт«џуџёnСИфТЮЃтђ╝wl№╝їw2№╝їРђд№╝їwnТъёТѕљnТБхС║їтЈЅТаЉуџёТБ«ТъЌF={T1№╝їT2№╝їРђд№╝їTn}№╝їтЁХСИГТ»ЈТБхС║їтЈЅТаЉTiСИГжЃйтЈфТюЅСИђСИфТЮЃтђ╝СИ║wiуџёТа╣у╗Њуѓ╣№╝їтЁХтидтЈ│тГљТаЉтЮЄуЕ║сђѓ
сђђсђђ(2)тюеТБ«ТъЌFСИГжђЅтЄ║СИцТБхТа╣у╗Њуѓ╣ТЮЃтђ╝Тюђт░ЈуџёТаЉ(тйЊУ┐ЎТаиуџёТаЉСИЇТГбСИцТБхТаЉТЌХ№╝їтЈ»С╗ЦС╗јСИГС╗╗жђЅСИцТБх)№╝їт░єУ┐ЎСИцТБхТаЉтљѕт╣ХТѕљСИђТБхТќ░ТаЉ№╝їСИ║С║єС┐ЮУ»ЂТќ░ТаЉС╗ЇТў»С║їтЈЅТаЉ№╝їжюђ УдЂтбътіаСИђСИфТќ░у╗Њуѓ╣СйюСИ║Тќ░ТаЉуџёТа╣№╝їт╣Хт░єТЅђжђЅуџёСИцТБхТаЉуџёТа╣тѕєтѕФСйюСИ║Тќ░Та╣уџётидтЈ│тГЕтГљ(У░Ђтид№╝їУ░ЂтЈ│ТЌатЁ│у┤ДУдЂ)№╝їт░єУ┐ЎСИцСИфтГЕтГљуџёТЮЃтђ╝С╣ІтњїСйюСИ║Тќ░ТаЉТа╣уџёТЮЃтђ╝сђѓ
сђђсђђ(3)т»╣Тќ░уџёТБ«ТъЌFжЄЇтцЇ(2)№╝їуЏ┤тѕ░ТБ«ТъЌFСИГтЈфтЅЕСИІСИђТБхТаЉСИ║ТГбсђѓУ┐ЎТБхТаЉСЙ┐Тў»тЊѕтцФТЏ╝ТаЉсђѓ
Т│еТёЈ№╝џ
РЉа тѕЮтДІТБ«ТъЌСИГуџёnТБхС║їтЈЅТаЉ№╝їТ»ЈТБхТаЉТюЅСИђСИфтГцуФІуџёу╗Њуѓ╣№╝їт«ЃС╗гТЌбТў»Та╣№╝їтЈѕТў»тЈХтГљ
РЉА nСИфтЈХтГљуџётЊѕтцФТЏ╝ТаЉУдЂу╗ЈУ┐Єn-1ТгАтљѕт╣Х№╝їС║ДућЪn-1СИфТќ░у╗Њуѓ╣сђѓТюђу╗ѕТ▒ѓтЙЌуџётЊѕтцФТЏ╝ТаЉСИГтЁ▒ТюЅ2n-1СИфу╗Њуѓ╣сђѓ
РЉб тЊѕтцФТЏ╝ТаЉТў»СИЦТа╝уџёС║їтЈЅТаЉ№╝їТ▓АТюЅт║дТЋ░СИ║1уџётѕєТћ»у╗Њуѓ╣сђѓ
С║ћ№╝џТюђС╝ўС║їтЈЅТаЉу«ЌТ│ЋтЁиСйЊт«ъуј░ТђЮУи»
тюеТъёжђатЊѕтцФТЏ╝ТаЉТЌХ№╝їтЈ»С╗ЦУ«Йуй«СИђСИфу╗ЊТъёТЋ░у╗ёHuffNodeС┐ЮтГўтЊѕтцФТЏ╝ТаЉСИГтљёу╗Њуѓ╣уџёС┐АТЂ»№╝їТа╣ТЇ«С║їтЈЅТаЉуџёТђДУ┤етЈ»уЪЦ№╝їтЁиТюЅnСИфтЈХтГљу╗Њуѓ╣уџётЊѕтцФТЏ╝ТаЉтЁ▒ТюЅ2n№╝Ї1СИфу╗Њуѓ╣№╝їТЅђС╗ЦТЋ░у╗ёHuffNodeуџётцДт░ЈУ«Йуй«СИ║2n№╝Ї1№╝їТЋ░у╗ётЁЃу┤ауџёу╗ЊТъётйбт╝ЈтдѓСИІ№╝џ
|
weight
|
lchild
|
rchild
|
parent
|
тЁХСИГ№╝їweightтЪЪС┐ЮтГўу╗Њуѓ╣уџёТЮЃтђ╝№╝їlchildтњїrchildтЪЪтѕєтѕФС┐ЮтГўУ»Цу╗Њуѓ╣уџётидсђЂтЈ│тГЕтГљу╗Њуѓ╣тюеТЋ░у╗ёHuffNodeСИГуџёт║ЈтЈи№╝їС╗јУђїт╗║уФІУхиу╗Њ уѓ╣С╣ІжЌ┤уџётЁ│у│╗сђѓСИ║С║єтѕцт«џСИђСИфу╗Њуѓ╣Тў»тљдти▓тіатЁЦтѕ░УдЂт╗║уФІуџётЊѕтцФТЏ╝ТаЉСИГ№╝їтЈ»жђџУ┐ЄparentтЪЪуџётђ╝ТЮЦуА«т«џсђѓтѕЮтДІТЌХparentуџётђ╝СИ║№╝Ї1№╝їтйЊу╗Њуѓ╣тіатЁЦтѕ░ТаЉСИГТЌХ№╝ї У»Цу╗Њуѓ╣parentуџётђ╝СИ║тЁХтЈїС║▓у╗Њуѓ╣тюеТЋ░у╗ёHuffNodeСИГуџёт║ЈтЈи№╝їт░▒СИЇС╝џТў»№╝Ї1С║єсђѓТъёжђатЊѕтцФТЏ╝ТаЉТЌХ№╝їждќтЁѕт░єућ▒nСИфтГЌугдтйбТѕљуџёnСИфтЈХу╗Њуѓ╣тГўТћЙтѕ░ТЋ░у╗ёHuffNodeуџётЅЇnСИфтѕєжЄЈСИГ№╝їуёХтљјТа╣ТЇ«тЅЇжЮбС╗Іу╗ЇуџётЊѕтцФТЏ╝Тќ╣Т│ЋуџётЪ║ТюгТђЮТЃ│№╝їСИЇТќГт░єСИцСИфт░ЈтГљТаЉтљѕт╣ХСИ║СИђСИфУЙЃтцДуџётГљТаЉ№╝їТ»ЈТгАТъёТѕљуџёТќ░тГљТаЉуџёТа╣у╗Њуѓ╣жА║т║ЈТћЙтѕ░HuffNodeТЋ░у╗ёСИГуџётЅЇnСИфтѕєжЄЈуџётљјжЮбсђѓ
тЁиСйЊт«ъуј░№╝џ
1№╝ЅтГўтѓеу╗ЊТъё
#define n 100 //тЈХу╗Њуѓ╣ТЋ░уЏ«
#define m 2*n-1 //ТаЉСИГу╗Њуѓ╣Тђ╗ТЋ░
typedef struct
{
floatweight; //ТЮЃтђ╝№╝їУ«ЙТЮЃтђ╝тЮЄтцДС║јжЏХ
intlchild,rchild,parent; //тидтЈ│тГЕтГљтЈітЈїС║▓ТїЄжњѕ
} HTNode;
typedef HTNode HuffmanTree[m]; //тЊѕтцФТЏ╝ТаЉТў»СИђу╗┤ТЋ░у╗ё
(2)УхФтцФТЏ╝у«ЌТ│ЋуџёТЋ░у╗ёТ│ЋТъёжђа
void CreateHuffmanTree(HuffmanTree T)
{
int i,p1,p2; //ТъёжђатЊѕтцФТЏ╝ТаЉ№╝їT[m-1]СИ║тЁХТа╣у╗Њуѓ╣
InitHuffmanTree(T); //TтѕЮтДІтїќ
InputWeight(T); //УЙЊтЁЦтЈХтГљТЮЃтђ╝УЄ│T[0№╝ј№╝јn-1]уџёweightтЪЪ
for(i=n;i<m;i++)
{
SelectMin(T,i-1,&p1,&p2);//тЁ▒У┐ЏУАїn-1ТгАтљѕт╣Х№╝їТќ░у╗Њуѓ╣СЙЮТгАтГўС║јT[i]СИГ
//тюеT[0Рђдi-1]СИГжђЅТІЕСИцСИфТЮЃТюђт░ЈуџёТа╣у╗Њуѓ╣№╝їтЁХт║ЈтЈитѕєтѕФСИ║p1тњїp2
T[p1].parent=T[p2].parent=i;
T[i].1child=p1; //Тюђт░ЈТЮЃуџёТа╣у╗Њуѓ╣Тў»Тќ░у╗Њуѓ╣уџётидтГЕтГљ
T[i].rchild=p2; //ТгАт░ЈТЮЃуџёТа╣у╗Њуѓ╣Тў»Тќ░у╗Њуѓ╣уџётЈ│тГЕтГљ
T[i].weight=T[p1].weight+T[p2].weight;
}//for
}//CreateHuffman
CУ»ГУеђт«ъуј░тЁежЃеС╗БуаЂ№╝џ
#include "stdio.h"
#include "stdlib.h"
#define m 100
struct ptree //т«џС╣ЅС║їтЈЅТаЉу╗Њуѓ╣у▒╗тъІ
{
int w; //т«џС╣Ѕу╗Њуѓ╣ТЮЃтђ╝
struct ptree *lchild; //т«џС╣ЅтидтГљу╗Њуѓ╣ТїЄжњѕ
struct ptree *rchild; //т«џС╣ЅтЈ│тГљу╗Њуѓ╣ТїЄжњѕ
};
struct pforest //т«џС╣ЅжЊЙУАеу╗Њуѓ╣у▒╗тъІ
{
struct pforest *link;
struct ptree *root;
};
int WPL=0; //тѕЮтДІтїќWTLСИ║0
struct ptree *hafm();
void travel();
struct pforest *inforest(struct pforest*f,struct ptree *t);
void travel(struct ptree *head,int n)
{
//СИ║жфїУ»Ђharfmу«ЌТ│ЋуџёТГБуА«ТђДУ┐ЏУАїуџёжЂЇтјє
struct ptree *p;
p=head;
if(p!=NULL)
{
if((p->lchild)==NULL && (p->rchild)==NULL) //тдѓТъюТў»тЈХтГљу╗Њуѓ╣
{
printf("%d ",p->w);
printf("the hops of the node is: %d/n",n);
WPL=WPL+n*(p->w); //У«Ау«ЌТЮЃтђ╝
}//if
travel(p->lchild,n+1);
travel(p->rchild,n+1);
}//if
}//travel
struct ptree *hafm(int n, int w[m])
{
struct pforest *p1,*p2,*f;
struct ptree *ti,*t,*t1,*t2;
int i;
f=(pforest *)malloc(sizeof(pforest));
f->link=NULL;
for(i=1;i<=n;i++) //С║ДућЪnТБхтЈфТюЅТа╣у╗Њуѓ╣уџёС║їтЈЅТаЉ
{
ti=(ptree*)malloc(sizeof(ptree));//т╝ђУЙЪТќ░уџёу╗Њуѓ╣уЕ║жЌ┤
ti->w=w[i]; //у╗Ўу╗Њуѓ╣УхІТЮЃтђ╝
ti->lchild=NULL;
ti->rchild=NULL;
f=inforest(f, ti);
//ТїЅТЮЃтђ╝С╗јт░Јтѕ░тцДуџёжА║т║Јт░єу╗Њуѓ╣С╗јСИітѕ░СИІтю░ТїѓтюеСИђжбЌТаЉСИі
}//for
while(((f->link)->link)!=NULL)//УЄ│т░ЉТюЅС║їТБхС║їтЈЅТаЉ
{
p1=f->link;
p2=p1->link;
f->link=p2->link; //тЈќтЄ║тЅЇСИцТБхТаЉ
t1=p1->root;
t2=p2->root;
free(p1); //жЄіТћЙp1
free(p2); //жЄіТћЙp2
t=(ptree *)malloc(sizeof(ptree));//т╝ђУЙЪТќ░уџёу╗Њуѓ╣уЕ║жЌ┤
t->w = (t1->w)+(t2->w); //ТЮЃуЏИтіа
t->lchild=t1;
t->rchild=t2; //С║ДућЪТќ░С║їтЈЅТаЉ
f=inforest(f,t);
}//while
p1=f->link;
t=p1->root;
free(f);
return(t); //У┐ћтЏъt
}
pforest *inforest(struct pforest *f,structptree *t)
{
//ТїЅТЮЃтђ╝С╗јт░Јтѕ░тцДуџёжА║т║Јт░єу╗Њуѓ╣С╗јСИітѕ░СИІтю░ТїѓтюеСИђжбЌТаЉСИі
struct pforest *p, *q, *r;
struct ptree *ti;
r=(pforest *)malloc(sizeof(pforest)); //т╝ђУЙЪТќ░уџёу╗Њуѓ╣уЕ║жЌ┤
r->root=t;
q=f;
p=f->link;
while (p!=NULL) //т»╗ТЅЙТЈњтЁЦСйЇуй«
{
ti=p->root;
if(t->w > ti->w) //тдѓТъюtуџёТЮЃтђ╝тцДС║јtiуџёТЮЃтђ╝
{
q=p;
p=p->link; //pтљЉтљјт»╗ТЅЙ
}//if
else
p=NULL; //т╝║У┐ФжђђтЄ║тЙфуј»
}//while
r->link=q->link;
q->link=r; //rТјЦтюеqуџётљјжЮб
return(f); //У┐ћтЏъf
}
void InPut(int &n,int w[m])
{
printf("please input the sum ofnode/n"); //ТЈљуц║УЙЊтЁЦу╗Њуѓ╣ТЋ░
scanf("%d",&n); //УЙЊтЁЦу╗Њуѓ╣ТЋ░
printf ("please input weight of everynode/n"); //ТЈљуц║УЙЊтЁЦТ»ЈСИфу╗Њуѓ╣уџёТЮЃтђ╝
for(int i=1;i<=n;i++)
scanf("%d",&w[i]); //УЙЊтЁЦТ»ЈСИфу╗Њуѓ╣ТЮЃтђ╝
}
int main( )
{
struct ptree *head;
int n,w[m];
InPut(n,w);
head=hafm(n,w);
travel(head,0);
printf("The length of the best path isWPL=%d", WPL);//УЙЊтЄ║ТюђСй│Уи»тЙёТЮЃтђ╝С╣Ітњї
return 1;
}
тѕєС║Фтѕ░№╝џ





уЏИтЁ│ТјеУЇљ
ТаЉу╗ЊТъёуџёуЅ╣уѓ╣Тў»№╝џт«ЃуџёТ»ЈСИђСИфу╗Њуѓ╣жЃйтЈ»С╗ЦТюЅСИЇТГбСИђСИфуЏ┤ТјЦтљју╗Д№╝їжЎцТа╣у╗Њуѓ╣тцќуџёТЅђТюЅу╗Њуѓ╣жЃйТюЅСИћтЈфТюЅСИђСИфуЏ┤ТјЦтЅЇУХІсђѓ
ТЉў УдЂ№╝џтЊѕтцФТЏ╝у╝ќуаЂТў»СИђуДЇТЋ░ТЇ«у╝ќуаЂТќ╣т╝Ј№╝їС╗ЦтЊѕтцФТЏ╝ТаЉРђћРђћтЇ│ТюђС╝ўС║їтЈЅТаЉ№╝їућетИдТЮЃУи»тЙёжЋ┐т║дТюђт░ЈуџёС║їтЈЅТаЉ№╝їт»╣ТЋ░ТЇ«У┐ЏУАїжЄЇу╝ќуаЂ№╝їу╗ЈтИИт║ћ ућеС║јТЋ░ТЇ«тјІу╝ЕсђѓтюеУ«Ау«ЌТю║С┐АТЂ»тцёуљєСИГ№╝їРђютЊѕтцФТЏ╝у╝ќуаЂРђЮТў»СИђуДЇСИђУЄ┤ТђДу╝ќуаЂТ│Ћ№╝ѕтЈѕуД░Рђюуєху╝ќуаЂТ│Ћ...
ТаЉуџёт«џС╣ЅтњїтЪ║ТюгТю»У»Г№╝џТа╣сђЂтГЕтГљсђЂтГљтГЎсђЂтЈїС║▓сђЂтЁёт╝ЪсђЂтаѓтЁёсђЂУи»тЙёуГЅ С║їтЈЅТаЉуџёт«џС╣ЅтЈі5СИфтЪ║ТюгТђДУ┤есђѓ...ТюђС╝ўС║їтЈЅТаЉуџёт«џС╣ЅсђЂТъёт╗║тЈітЊѕтцФТЏ╝у╝ќуаЂуџёТъёжђасђѓ ТаЉуџётГўтѓеТќ╣т╝Јсђѓ ТаЉТѕќТБ«ТъЌСИјС║їтЈЅТаЉС╣ІжЌ┤уџёуЏИС║њУйгтїќ ТаЉтЈіТБ«ТъЌуџёжЂЇтјєТќ╣Т│Ћ
1сђЂтЊѕтцФТЏ╝ТаЉС╣ЪуД░ТюђС╝ўС║їтЈЅТаЉ№╝їтюет«ъжЎЁСИГТюЅуЮђт╣┐Т│Џуџёт║ћућесђѓ тЈХтГљУіѓуѓ╣уџёТЮЃтђ╝ Тў»т»╣тЈХтГљу╗Њуѓ╣УхІС║ѕуџёСИђСИфТюЅТёЈС╣ЅуџёТЋ░тђ╝жЄЈсђѓ С║їтЈЅТаЉуџётИдТЮЃУи»тЙёжЋ┐т║д У«ЙС║їтЈЅТаЉтЁиТюЅnСИфтИдТЮЃтђ╝уџётЈХтГљУіѓуѓ╣№╝їС╗јТа╣Уіѓуѓ╣тѕ░тЈХтГљУіѓуѓ╣уџёУи»тЙёжЋ┐т║дСИјуЏИт║ћуџётЈХтГљ...
тЁФТќ╣тљЉУ┐ит«Фуџёт«ъуј░ тєЁжЎёУ»ду╗єуџёуеІт║ЈУ»┤У»┤Тўј У┐ўТюЅТаЉуџёуЏИтЁ│уеІт║Ј тЊѕтцФТЏ╝ТаЉ№╝ѕHuffmanТаЉ№╝ЅРђћРђћУ«ЙТюЅnСИфТЮЃтђ╝{w1,w2,РђдРђдwn}№╝їТъёжђаСИђТБхТюЅnСИфтЈХтГљу╗Њуѓ╣уџёС║їтЈЅТаЉ№╝їТ»ЈСИфтЈХтГљуџёТЮЃтђ╝СИ║wi,тѕЎwplТюђт░ЈуџёС║їтЈЅТаЉтЈФ~№╝їС╣ЪуД░ТюђС╝ўС║їтЈЅТаЉ
У»Йжбў:сђітЊѕтцФТЏ╝ТаЉу╝ќуаЂУДБуаЂсђІ СИђсђЂт«ъжфїтєЁт«╣ У┐љућетЊѕтцФТЏ╝у╝ќуаЂуџёуЏИтЁ│уЪЦУ»єт»╣С╗╗ТёЈТќЄТюгТќЄС╗ХУ┐ЏУАїу╝ќуаЂсђЂУДБуаЂсђѓ С║їсђЂжюђУдЂућеуџёТЋ░ТЇ«у╗ЊТъёС╗ЦтЈіт«ъуј░ТђЮУи» жюђУдЂућетѕ░С║їтЈЅТаЉсђЂHuffManТаЉсђЂжђњтйњуГЅТЋ░ТЇ«у╗ЊТъё С║їтЈЅТаЉ тюеУ«Ау«ЌТю║уДЉтГдСИГ№╝їС║їтЈЅТаЉТў»...
*5.6 C№╝І№╝ІтцёуљєтГЌугдСИ▓уџёТќ╣Т│ЋРђћРђћтГЌугдСИ▓у▒╗СИјтГЌугдСИ▓тЈўжЄЈ 5.6.1 тГЌугдСИ▓тЈўжЄЈуџёт«џС╣Ѕтњїт╝Ћуће 5.6.2 тГЌугдСИ▓тЈўжЄЈуџёУ┐љу«Ќ 5.6.3 тГЌугдСИ▓ТЋ░у╗ё 5.6.4 тГЌугдСИ▓У┐љу«ЌСИЙСЙІ С╣ажбў угг6уФа ТїЄжњѕ 6.1 ТїЄжњѕуџёТдѓт┐х 6.2 тЈўжЄЈСИјТїЄжњѕ 6.2.1 т«џС╣Ѕ...
*5.6 C№╝І№╝ІтцёуљєтГЌугдСИ▓уџёТќ╣Т│ЋРђћРђћтГЌугдСИ▓у▒╗СИјтГЌугдСИ▓тЈўжЄЈ 5.6.1 тГЌугдСИ▓тЈўжЄЈуџёт«џС╣Ѕтњїт╝Ћуће 5.6.2 тГЌугдСИ▓тЈўжЄЈуџёУ┐љу«Ќ 5.6.3 тГЌугдСИ▓ТЋ░у╗ё 5.6.4 тГЌугдСИ▓У┐љу«ЌСИЙСЙІ С╣ажбў угг6уФа ТїЄжњѕ 6.1 ТїЄжњѕуџёТдѓт┐х 6.2 тЈўжЄЈСИјТїЄжњѕ 6.2.1 т«џС╣Ѕ...
050 С║їтЈЅТљюу┤бТаЉТЊЇСйю 051 С║їжА╣т╝Ју│╗ТЋ░жђњтйњ 052 УЃїтїЁжЌ«жбў 053 жА║т║ЈУАеТЈњтЁЦтњїтѕажЎц 054 жЊЙУАеТЊЇСйю№╝ѕ1№╝Ѕ 055 жЊЙУАеТЊЇСйю№╝ѕ2№╝Ѕ 056 тЇЋжЊЙУАет░▒тю░жђєуй« 057 У┐љтіеС╝џтѕєТЋ░у╗ЪУ«А 058 тЈїжЊЙУАе 059 у║дуЉЪтцФуј» 060 У«░тйЋСИфС║║УхёТќЎ ...
ТаЉ4.1 жбётцЄуЪЦУ»є4.1.1 ТаЉуџёт«ъуј░4.1.2 ТаЉуџёжЂЇтјєтЈіт║ћуће4.2 С║їтЈЅТаЉ4.2.1 т«ъуј░4.2.2 СЙІтГљ№╝џУАеУЙЙт╝ЈТаЉ4.3 ТЪЦТЅЙТаЉADTРђћРђћС║їтЈЅТЪЦТЅЙТаЉЬђЄ4.3.1 containsТќ╣Т│Ћ4.3.2 findMinТќ╣Т│ЋтњїfindMaxТќ╣Т│Ћ4.3.3 insertТќ╣Т│Ћ4.3.4 removeТќ╣Т│Ћ...
УАеУЙЙт╝ЈТаЉсђђ4.3сђђТЪЦТЅЙТаЉadtРђћРђћС║їтЈЅТЪЦТЅЙТаЉЬђЄсђђ4.3.1сђђcontainsТќ╣Т│Ћсђђ4.3.2сђђfindminТќ╣Т│ЋтњїfindmaxТќ╣Т│Ћсђђ4.3.3сђђinsertТќ╣Т│Ћсђђ4.3.4сђђremoveТќ╣Т│Ћсђђ4.3.5сђђт╣│тЮЄТЃЁтєхтѕєТъљсђђ4.4сђђavlТаЉсђђ4.4.1сђђтЇЋТЌІУйгсђђ4.4.2сђђтЈїТЌІУйгсђђ4.5...
УАеУЙЙт╝ЈТаЉсђђ4.3сђђТЪЦТЅЙТаЉadtРђћРђћС║їтЈЅТЪЦТЅЙТаЉЬђЄсђђ4.3.1сђђcontainsТќ╣Т│Ћсђђ4.3.2сђђfindminТќ╣Т│ЋтњїfindmaxТќ╣Т│Ћсђђ4.3.3сђђinsertТќ╣Т│Ћсђђ4.3.4сђђremoveТќ╣Т│Ћсђђ4.3.5сђђт╣│тЮЄТЃЁтєхтѕєТъљсђђ4.4сђђavlТаЉсђђ4.4.1сђђтЇЋТЌІУйгсђђ4.4.2сђђтЈїТЌІУйгсђђ4.5...
ТаЉ4.1 жбётцЄуЪЦУ»є4.1.1 ТаЉуџёт«ъуј░4.1.2 ТаЉуџёжЂЇтјєтЈіт║ћуће4.2 С║їтЈЅТаЉ4.2.1 т«ъуј░4.2.2 СЙІтГљ№╝џУАеУЙЙт╝ЈТаЉ4.3 ТЪЦТЅЙТаЉADTРђћРђћС║їтЈЅТЪЦТЅЙТаЉЬђЄ4.3.1 containsТќ╣Т│Ћ4.3.2 findMinТќ╣Т│ЋтњїfindMaxТќ╣Т│Ћ4.3.3 insertТќ╣Т│Ћ4.3.4 removeТќ╣Т│Ћ...
ТаЉ4.1 жбётцЄуЪЦУ»є4.1.1 ТаЉуџёт«ъуј░4.1.2 ТаЉуџёжЂЇтјєтЈіт║ћуће4.2 С║їтЈЅТаЉ4.2.1 т«ъуј░4.2.2 СЙІтГљ№╝џУАеУЙЙт╝ЈТаЉ4.3 ТЪЦТЅЙТаЉADTРђћРђћС║їтЈЅТЪЦТЅЙТаЉЬђЄ4.3.1 containsТќ╣Т│Ћ4.3.2 findMinТќ╣Т│ЋтњїfindMaxТќ╣Т│Ћ4.3.3 insertТќ╣Т│Ћ4.3.4 removeТќ╣Т│Ћ...
4.3 ТЪЦТЅЙТаЉADTРђћРђћС║їтЈЅТЪЦТЅЙТаЉЬђЄ 4.3.1 containsТќ╣Т│Ћ 4.3.2 findMinТќ╣Т│ЋтњїfindMaxТќ╣Т│Ћ 4.3.3 insertТќ╣Т│Ћ 4.3.4 removeТќ╣Т│Ћ 4.3.5 т╣│тЮЄТЃЁтєхтѕєТъљ 4.4 AVLТаЉ 4.4.1 тЇЋТЌІУйг 4.4.2 тЈїТЌІУйг 4.5 С╝Ит▒ЋТаЉ 4.5.1 СИђСИфу«ђтЇЋуџёТЃ│Т│Ћ...