前几篇系列博客:
细谈Hibernate(一)hibernate基本概念和体系结构
细谈Hibernate(二)开发第一个hibernate基本详解
细谈Hibernate(三)Hibernate常用API详解及源码分析
细谈Hibernate(四)Hibernate常用配置文件详解
在前几篇博客,我们初步对Hibernate有了一定的基础性的认知了,也能够简单的用hibernate进行增删改查,但hibernate真正的难度和精髓我们都还没接触到,其中最主要的关联映射就是其中一个,这篇博客,我们就一起来看一下这个hibernate关联映射。我们大家都知道,在域模型(实体域)中,关联关系是类与类之间最普遍的关系,他是指通过一个对象持有另一个对象的实例根据UML语言,关系是有方向的。实质上关联映射的本质:将关联关系映射到数据库,所谓的关联关系是对象模型在内存中的一个或多个引用。搞清关联映射的的关键就在于搞清实体之间的关系。下面我们首先来看一下具体什么事关联关系:
一:关联关系
1.关联关系的方向可分为单向关联和双向关联。
单向关联:假设存在两张表person表和address表,如果在应用的业务逻辑中,仅需要每个person实例能够查询得到其对应的Address实例,而Address实例并不需要查询得到其对应的person实例;或者反之。
双向关联:既需要每个person实例能够查询得到其对应的Address实例,Address实例也需要查询得到其对应的person实例。
2.关联的数量,根据拥有被关联对象的个数确定
多对一(manytoone):如用户和组学生和班级
一对多(onetomany):如用户和电子邮件
多对多(manytomany):如学生选课
一对一(onetoone):如用户和身份证
下面我们就开始讲第一种关联关系:一对多,一对多总共分为:单向一对多,单向多对一,双向一对多。这主要是站在关系双方各自角度来定义的。下面我们就来一一来看一下
二.单向多对一
单向多对一关联是最常见的单向关联关系,如:多个用户属于同一个组,多个学生处于同一个班级。之所以叫他多对一而不是一对多,是因为他们之间的关系是多的一方来维护的,下面我们就以多个用户属于同一个组来详细说明一下单向多对一。首先看一下他们的关系示例:

从上边的图示中可以看出,多个用户属于一个组,我们用多的一方来维护,所以我们可以根据用户可以知道他在哪个组,而不需要知道一个组里有哪些学生,这就是所谓的单向的。多对一映射原理:在多的一端加入一个外键指向一的一端,它维护的关系多指向一,一对多映射原理,在多的一端加入一个外键指向一的一端,她维护的关系是一指向多,也就是说一对多与多对一的映射原理是一样的,只是站的角度不一样。下面来看一下单向多对一关系配置文件:
Group:一的一方,不需要维护关系,所以和普通配置一样
<hibernate-mapping>
<class name="cn.edu.bzu.manytoone.entity.Group" table=“group">
<id name="id">
<column name="id" />
<generator class="native" />
</id>
<property name="name" type="java.lang.String">
<column name="name" length="50" not-null="true" />
</property>
</class>
</hibernate-mapping>
User:多的一方,需要维护双方关系,内有一的一方引用:
<hibernate-mapping>
<class name="cn.edu.bzu.manytoone.entity.User" table=“user”>
<id name="id">
<column name="id" />
<generator class="native" />
</id>
<many-to-one name=“group” column =“group_id”/>
</many-to-one>
<property name="name" type="java.lang.String">
<column name="street_name" length="50" not-null="true" />
</property>
</class>
</hibernate-mapping>
注:1.many-to-one元素的常用属性:
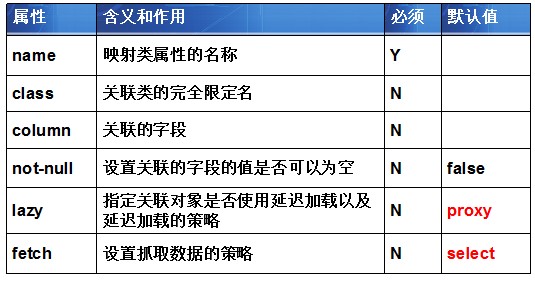
具体的抓取数据策略会再以后详细讲解
2.重要属性-cascade(级联)
级联的意思是指定两个对象之间的操作联动关系,对一个对象执行了操作之后,对其指定的级联对象也需要执行相同的操作
总共可以取值为:all、none、save-update、delete
all-代表在所有的情况下都执行级联操作
none-在所有情况下都不执行级联操作
save-update-在保存和更新的时候执行级联操作
delete-在删除的时候执行级联操作
三.单向一对多
所谓单向一对多,就是实体之间的关系由“一”的一端加载“多”的一端,关系由“一”的一端来维护,在JavaBean中是在“一”的一端中持有“多”的一端的集合,Hibernate把这种关系反映到数据库的策略是在“多”的一端的表上加一个外键指向“一”的一端的表的主键。比如Class(班级)和Student(学生)之间是一对多的关系。一个班级里面有很多的学生,站在班级的角度上来看就是一个班级对应多个学生。我们来看一下具体的关系图:
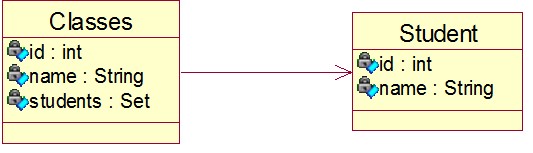
从图上我们可以看出,在一的一端含有一个多的引用的集合,我们可以根据班级找到它有哪些学生,而不能根据学生找到他对应的班级。在一的一端维护的缺点:
*如果将student表里的classesid设为非空,则无法保存;
*因为不是在student端维护数据,所以student端不知道学生是哪个班的
*需要发出多余的update语句来更新关系;
下面我们就具体来看一下一对多中维护关系的“一”中是怎么样来配置的:Class映射文件
<hibernate-mapping>
<class name="cn.edu.bzu.hibernate.Class" table=“tb_class”>
<id name="id">
<generator class=“native"/>
</id>
<property name="name"/>
<set name="students" >
<key column="classid" ></key>
<one-to-many class=“cn.edu.bzu.hibernate.Student" />
</set>
</class>
</hibernate-mapping>
注意:
1.<set>元素的inverse属性:在映射一对多的双向关联时,应该在“one”方把inverse属性设为true,这样可提高应用性能。
inverse:控制反转,为true表示反转,由它方负责;反之,不反转,自己负责;如果不设,one和many两方都要负责控制,因此,会引发重复的sql语句以及重复添加数据,
2.级联删除(从数据库删除相关表记录)
当删除Customer对象时,及联删除Order对象.只需将cascad属性设为delete即可.
注:删除后的对象,依然存在于内存中,只不过由持久化态变为临时态.
3.父子关系(逻辑删除,只是解除了关联关系)
自动删除不再和Customer对象关联的Order对象.只需将cascade属性设为delete-orphan.
注:当关联双方都存在父子关系,就可以把父方的cascade属性设为delete-orphan,所谓父子关系,是由父方来控制子方的生命周期.
4.<setname="students">
<keycolumn="classid"></key>
<one-to-manyclass=“cn.edu.bzu.hibernate.Student"/>
</set>
Name为--持久化对象的集合的属性名称
<keycolumn="classid"></key>外键的名称
<one-to-manyclass=“cn.edu.bzu.hibernate.Student"/>持久化类
四:双向一对多关联
所谓双向一对多关联,同时配置单向一对多和单向多对一就成了双向一对多关联,上面两种都是单向的,但是在实际开发过程中,很多时候都是需要双向关联的,它在解决单向一对多维护关系的过程中存在的缺陷起了一定的修补作用。在插入学生的时候,如果班级不能为空,则学生是插入不了的。还有如果插入成功,在开始解决班级字段是空的,在事务提交阶段,班级需要更新每一个学生的班级ID,这样会产生大量的Update语句。影响效率。所以一对多关系大多使用双向一对多映射。具体配置文件:
多的一方:Student映射文件
<hibernate-mapping>
<class name="cn.edu.bzu.hibernate.Student">
<id name="id">
<generator class=“native"/>
</id>
<property name="name"/>
<many-to-one name=“classes” column=“classid”/>
</class>
</hibernate-mapping>
一的一方:Class映射文件
<hibernate-mapping>
<class name="cn.edu.bzu.hibernate.Class" table=“tb_class”>
<id name="id">
<generator class=“native"/>
</id>
<property name="name"/>
<set name="students">
<key column="classid" ></key>
<one-to-many class=“cn.edu.bzu.hibernate.Student" />
</set>
</class>
</hibernate-mapping>
注:
1.一对多双向关联映:
*在一的一端的集合上使用<key>,在对方表中加入一个外键指向一的一端;
*在多一端采用<many-to-one>
2.key标签指定的外键字段必须和<many-to-one>指定的外键字段一致,否则引用字段错误;
3.如果在一的一端维护一对多关联关系,hibernate会发出多余的Update语句,多以我们一般在多的一端维护关联关系
4.关于inverse属性;
inverse主要用在一对多,多对对双向关联上,inverse可以设置到<set>集合上,
默认inverse为false,所以我们可以从一的一端和多的一端来维护关联关系,如果inverse为true,我们只能从多的一端来维护关联关系,注意:inverse属性,只影响存储(使存储方向转变),即持久,
5.区分inverse和cascade
Inverse:负责控制关系,默认为false,也就是关系的两端都能控制,但这样会造成一些问题,更新的时候会因为两端都控制关系,于是重复更新。一般来说有一端要设为true。
Cascade:负责控制关联对象的级联操作,包括更新、删除等,也就是说对一个对象进行更新、删除时,其它对象也受影响,比如我删除一个对象,那么跟它是多对一关系的对象也全部被删除。
举例说明区别:删除“一”那一端一个对象O的时候,如果“多”的那一端的Inverse设为true,则把“多”的那一端所有与O相关联的对象外键清空;如果“多”的那一端的Cascade设为Delete,则把“多”的那一端所有与O相关联的对象全部删除。





相关推荐
JAVA程序员 从笨鸟到菜鸟
java程序员-从笨鸟到菜鸟.pdf
自学道路上的迷惑,所以从2012 年2 月份开始着手《java 程序员从笨鸟 到菜鸟》的编写。真心希望可以帮助刚起步学习java 开发的兄弟姐妹们。 没参与过中大型项目的开发,没有高的学历。所以此人之书只能供参考。
java程序员由菜鸟到笨鸟 作者:曹胜欢
java比较好的一篇文档,作者写的比较细,主要是一些基础概念说的比较细。
本电子书涵盖了从java基础到javaweb开放框架的大部分内容。在编写的过程中,难免会出现一些错误,希望大家能多多提些意见。
资源名称:《Java程序员-从笨鸟到菜鸟》PDF 下载资源目录:作者简介:..........................................................................................................................................
java程序员由菜鸟到笨鸟 一本值得java程序员看的书籍 给大家分享一下 喜欢的评个好评 谢谢
java程序员由菜鸟到笨鸟 作者:曹胜欢
java程序员由菜鸟到笨鸟 作者:曹胜欢
1.背景02. Netty 高性能之道0第 4 章第 4 章Java 数据库和网络Java 数据库和网络00Java 数据库操作0java 程序员从笨鸟到菜鸟之
摘要视图订阅曹胜欢欢迎关注微信账号:java那些事:csh624366188.每天一篇java相关的文章登录 | 注册Java程序员从笨鸟到菜鸟(81)3054